XGBoost란?
XGBoost는 Gradient Boosting 알고리즘의 한 종류입니다. Gradient Boosting은 여러 개의 결정 트리를 사용하여 앙상블 모델을 만드는 방식입니다. 각 트리는 이전 트리의 오차를 보완하도록 만들어지며, 이를 통해 모델의 예측 성능을 향상시킵니다.
XGBoost는 Gradient Boosting의 장점을 살리면서, 더욱 빠르고 정확한 모델을 만들 수 있도록 개선된 알고리즘입니다. 이를 위해 다양한 기능을 제공하며, 병렬 처리와 메모리 최적화를 지원합니다.
XGBoost의 사용 예시
다음은 XGBoost를 사용한 예시 중 2개입니다.
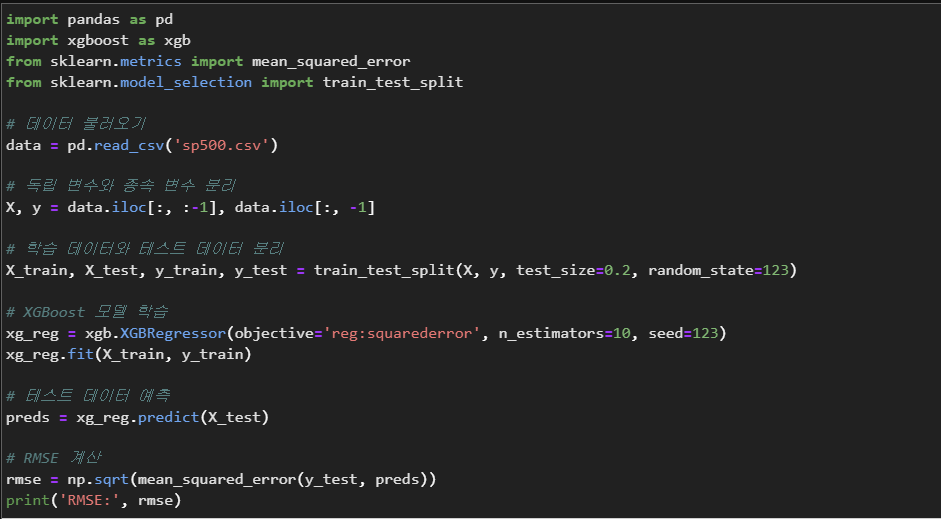
예시 1: 주가 예측
XGBoost를 이용하여 주가를 예측하는 모델을 만들어보겠습니다. 이를 위해, 2015년부터 2020년까지의 S&P 500 지수 데이터를 사용합니다.
예시 2: 이진 분류
XGBoost를 이용하여 이진 분류 모델을 만들어보겠습니다. 이를 위해, 와인 품질 데이터를 사용합니다.
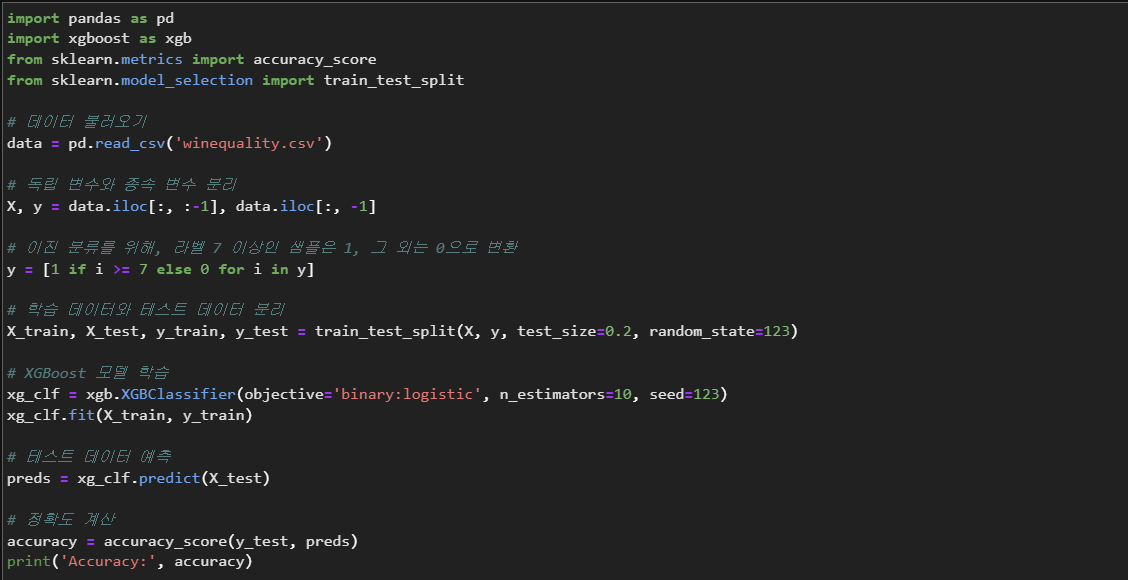
위 코드는 와인 품질 데이터를 이용하여 XGBoost를 사용한 이진 분류 예시입니다. XGBoost는 이진 분류에도 뛰어난 성능을 보여주며, 다양한 하이퍼파라미터를 조정하여 모델의 성능을 높일 수 있습니다.
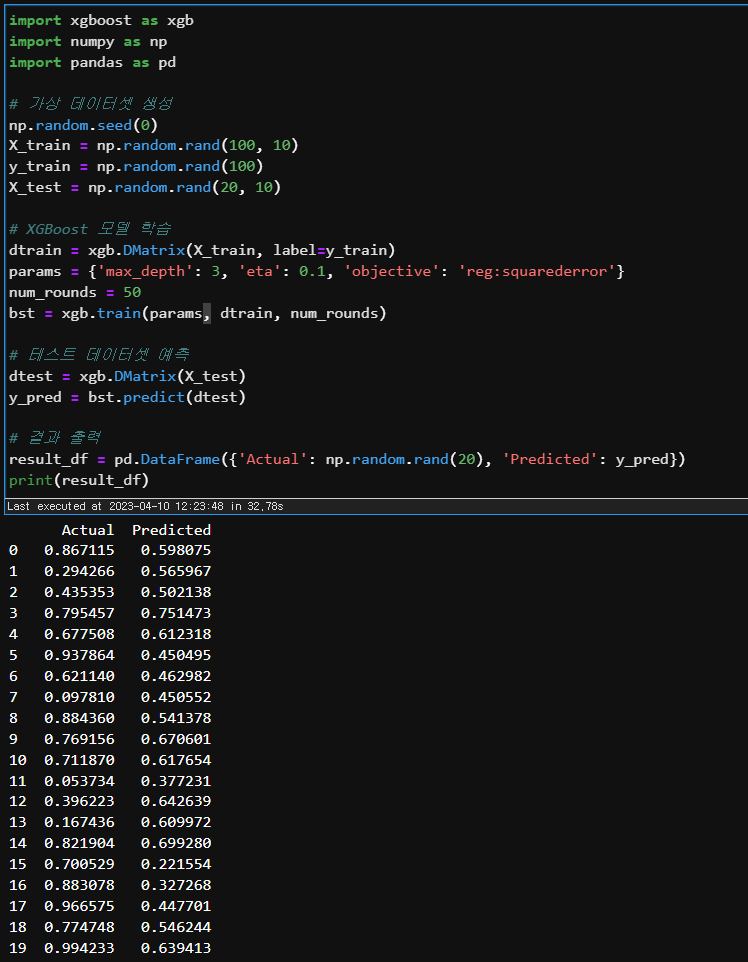
예시 1: 회귀 분석
가상의 주가 데이터셋을 생성하여 XGBoost를 이용해 종가를 예측해보겠습니다.
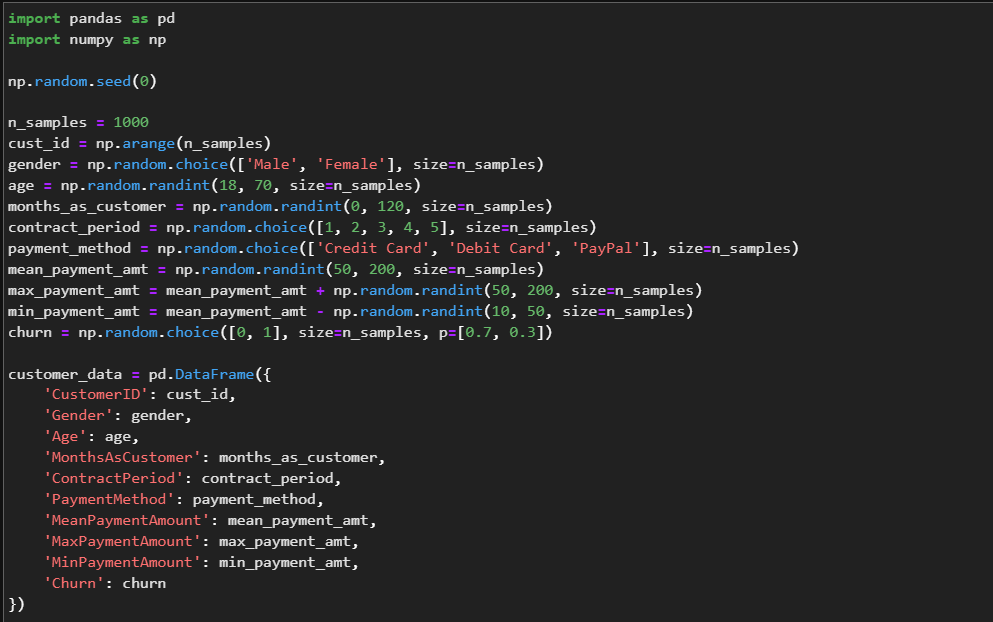
예시 2: 이진 분류
가상의 고객 데이터셋을 생성하여 XGBoost를 이용해 고객 이탈 여부를 예측해보겠습니다. 이 데이터셋은 다음과 같이 구성되어 있습니다.
-고객 ID
-성별
-나이
-가입 개월 수
-가입한 계약 기간
-결제 방식
-월별 평균 결제 금액
-월별 최대 결제 금액
-월별 최소 결제 금액
-고객 이탈 여부 (1: 이탈, 0: 이탈하지 않음)
다음으로 데이터를 전처리하겠습니다.
여기서는 성별과 결제 방식 변수를 원-핫 인코딩하고, 고객 ID를 제거하겠습니다.
데이터셋을 학습용과 테스트용으로 나누겠습니다.

XGBoost 모델을 학습시켜보겠습니다.
다음은 학습에 사용할 매개변수입니다.
-max_depth: 트리의 최대 깊이
-learning_rate: 학습 속도 조절 (0~1 사이 값)
-n_estimators: 생성할 트리의 개수
-objective: 최소화할 손실 함수 (이진 분류: 'binary:logistic', 다중 분류: 'multi:softmax')
-eval_metric: 평가 지표 (이진 분류: 'auc', 다중 분류: 'merror' 또는 'mlogloss')

정확도는 0.95로 매우 높은 수치를 보이고 있습니다.
오차 행렬을 통해 알 수 있듯이, 이 모델은 대체로 잘 예측하고 있습니다.
이제 이 모델을 실제 데이터에 적용하여 고객 이탈 여부를 예측해 볼 수 있습니다.