DFS 알고리즘이란?
DFS(Depth First Search)는 그래프를 탐색하는 알고리즘 중 하나로, 하나의 경로를 따라 최대한 깊게 들어가면서 그래프를 탐색합니다. 이때 스택(Stack) 자료구조를 사용하여 구현할 수 있습니다.
DFS는 깊이 우선 탐색 알고리즘이기 때문에, 그래프의 깊은 부분부터 탐색을 시작합니다. 그리고 현재 노드의 인접한 노드들을 스택에 push한 다음, 스택에서 pop하여 방문한 노드는 방문한 노드로 표시합니다. 이후 방문한 노드의 인접한 노드들을 스택에 push하고, 스택에서 pop한 다음 방문합니다. 이 과정을 반복하여 모든 노드를 탐색합니다.
DFS는 그래프의 구조를 파악할 수 있으며, 해결해야 하는 문제가 그래프 형태로 표현될 때 많이 사용됩니다. 예를 들어, 그래프에서 연결된 요소의 개수를 구하거나, 노드 간의 경로를 찾는 문제 등이 있습니다.
DFS 알고리즘의 예제 코드
다음은 DFS 알고리즘을 Python 언어로 구현한 예제 코드입니다.
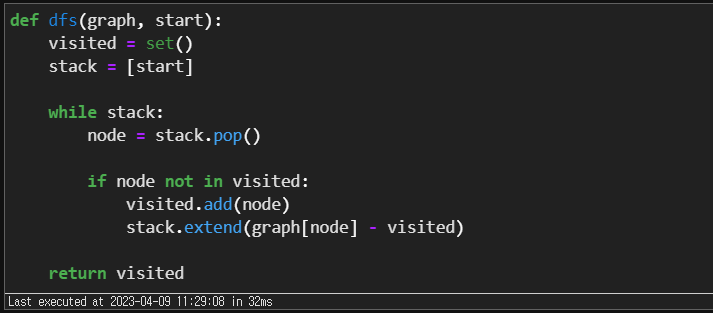

위 코드에서 graph는 그래프를 나타내는 인접 리스트(Adjacency List)입니다. start는 시작 노드를 나타내며, visited는 방문한 노드들의 집합(set)입니다. stack은 DFS를 수행하는 스택(Stack)입니다.
위 코드를 간단히 설명하자면, 시작 노드 start를 스택에 push한 후, 스택이 빌 때까지 다음을 반복합니다.
스택에서 노드 node를 pop합니다.
node가 visited에 없으면, visited에 node를 추가합니다.
node의 인접한 노드들 중 visited에 없는 노드를 스택에 push합니다.
2-3번 과정을 스택이 빌 때까지 반복합니다.
이와 같은 방식으로 모든 노드를 탐색한 후, visited 집합을 반환합니다.
DFS 알고리즘의 예제 코드 2
다음은 DFS 알고리즘을 Python으로 구현한 다른 예제 코드입니다.


위 코드에서 graph는 그래프를 나타내는 인접 리스트(Adjacency List)입니다. start는 시작 노드를 나타내며, visited는 방문한 노드들의 집합(set)입니다.
위 코드를 간단히 설명하자면, 시작 노드 start를 방문한 노드들 visited에 추가합니다. 그리고 start의 인접한 노드들 중 visited에 없는 노드를 재귀적으로 dfs 함수에 전달합니다. 이와 같은 방식으로 모든 노드를 탐색한 후, visited 집합을 반환합니다.