TensorRT-LLM은 NVIDIA의 고성능 추론 엔진인 TensorRT를 기반으로 하여, LLM의 추론을 최적화하고 가속화하는 데 중점을 둔 라이브러리입니다. 이를 통해 GPT-J, LLaMA, Falcon, Mistral 등 다양한 모델을 NVIDIA GPU에서 효율적으로 실행할 수 있습니다 .
+ NVIDIA에서 개발한 오픈 소스 라이브러리로, 대규모 언어 모델(LLM)의 추론 성능을 NVIDIA GPU에서 최적화하고 가속화하기 위해 설계되었으며, 이 라이브러리는 Python API를 통해 LLM을 정의하고, TensorRT 엔진을 구축하여 효율적인 추론을 수행할 수 있도록 지원한다고 합니다.
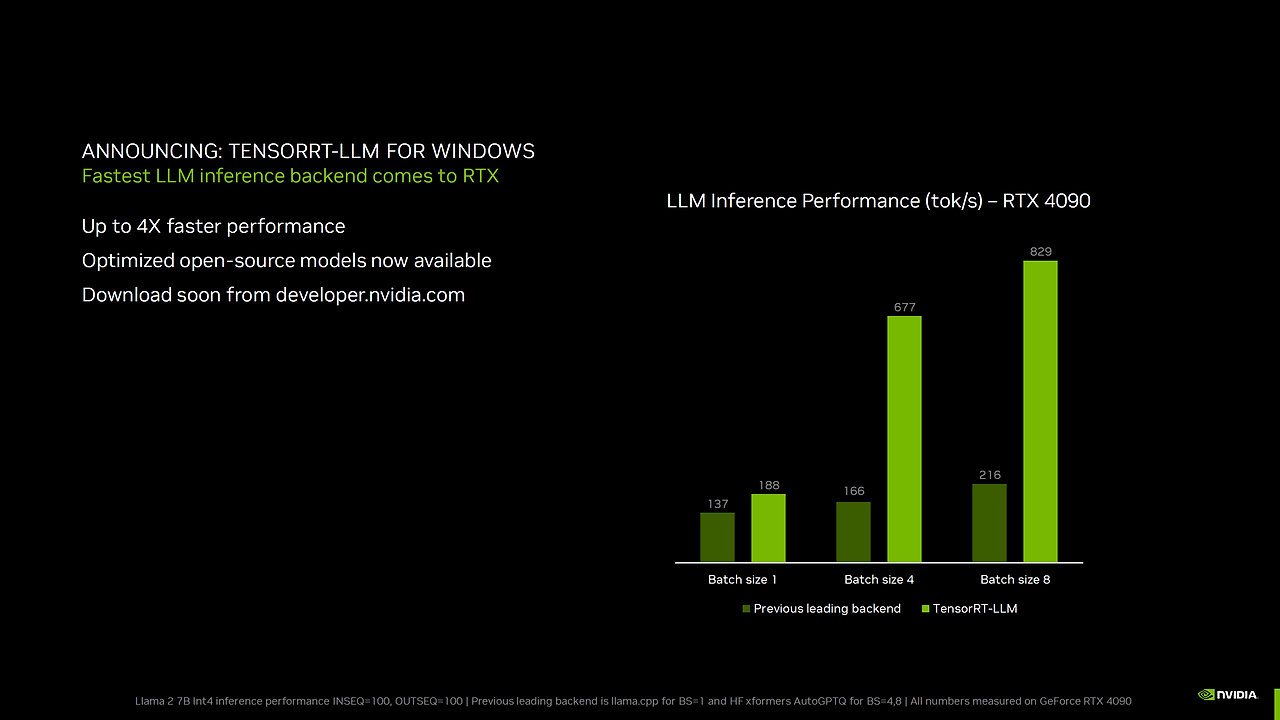
+ TensorRT-LLM은 다양한 LLM을 지원하며, NVIDIA H100 GPU에서 A100 대비 최대 8배의 추론 성능 향상을 보여준다고함.
주요 기능 및 최신 트렌드
양자화 지원
TensorRT-LLM은 FP8, FP4, INT4, INT8 등 다양한 정밀도를 지원하여 모델의 메모리 사용량을 줄이고 추론 속도를 향상시킨다. 예를 들어, INT4 AWQ를 적용한 Falcon-180B 모델은 A100 GPU 대비 6.7배 빠른 성능을 보인다.
In-Flight Batching
동적으로 배치를 관리하여 GPU 자원을 효율적으로 활용하고 지연 시간을 최소화한다. 이 기술을 통해 LLM의 텍스트 생성 과정에서 완료된 시퀀스를 즉시 제거하고 새로운 요청을 처리할 수 있다.
Paged KV 캐싱
키-값 캐시를 효율적으로 관리하여 긴 시퀀스의 추론 성능을 개선하며, 이 기능은 특히 긴 문장을 처리할 때 메모리 사용량을 줄이고 속도를 높이는 데 유용하다.
Speculative Decoding
예측 기반 디코딩을 통해 토큰 생성을 가속화하며, 최대 3.6배의 속도 향상을 제공한다. 이 기술은 작은 드래프트 모델과 큰 타겟 모델을 함께 사용하여 추론 속도를 높인다.
다중 GPU 및 노드 지원
Tensor Parallelism과 Pipeline Parallelism을 통해 대규모 모델을 다중 GPU 및 노드에서 효율적으로 실행할 수 있다. 이를 통해 대규모 모델의 추론을 분산하여 처리할 수 있다.
멀티블록 어텐션(Multiblock Attention)
멀티블록 어텐션은 디코딩 단계에서 GPU의 모든 스트리밍 멀티프로세서(SM)를 활용하여 처리량을 증가시키는 기능이다. 이 기능은 긴 시퀀스의 추론 성능을 최대 3.5배 향상시킨다.
청크드 프리필(Chunked Prefill)
청크드 프리필은 긴 컨텍스트를 처리할 때 GPU 활용도를 높이고, 개발자의 배포 경험을 간소화한다. 이 기능은 시스템 프리필이 필요한 사용 사례에서 성능을 최대 5배까지 향상시킨다.
다양한 디코딩 모드 지원
TensorRT-LLM은 다양한 디코딩 모드를 지원하여 다양한 생성 전략을 구현할 수 있다. 지원되는 디코딩 모드에는 Top-k, Top-p, Beam Search, Medusa, ReDrafter, Lookahead, Eagle 등이 포함된다.
활용 가능한 사례
실시간 챗봇
빠른 응답이 필요한 챗봇에서 낮은 지연 시간과 높은 처리량을 제공한다.
대규모 문서 요약
긴 문서를 빠르게 요약하여 정보 추출에 활용할 수 있다.
멀티모달 AI
텍스트와 이미지를 함께 처리하는 멀티모달 모델의 추론을 가속화한다.
온프레미스 AI 서버
자체 서버에서 LLM을 실행하여 데이터 프라이버시를 유지하면서도 고성능 추론을 실현할 수 있다.